7.1.4.1. Crawlers and Crawling
7.1.4.1.1. What is web crawler/Spider/Robot?
A web crawler is a computer program that visit web pages in an organized way. For example, Google's googlebot, Yahoo's Yahoo!Slurp, Bing's Bingbot, Adidxbot, MSNbot, MSBBotMedia, BingPreview.
Google now uses multiple crawlers :
- Googlebot
- Googlebot News
- Googlebot Images
- Googlebot Video
- Google Mobile Smartphone
- Google Mobile AdSense
- Google AdsBot
- Google app crawler

7.1.4.1.2. What is crawling issues?
7.1.4.1.2.1. How to crawl?
- Quality : how to find the best page first?
- Efficiency : how to avoid duplication(or near duplication)
- Etiquette : behave politely by not disturbing a website's performance
7.1.4.1.2.2. How much to crawl? How much to index?
- Coverage : What percentage of the web should be covered?
- Relative Coverage : How much do competitors have?
7.1.4.1.2.3. How often to crawl?
- Freshness : How much has changed? How much has really changes?
7.1.4.1.2.4. Complications && More Issues:
- crawling the entire page isn't feasible with one machine ==>
- latency/bandwidth to remote server can vary widely
- avoiding malicious pages : spam, spider traps(dynamically generated pages)
- Robots.txt can prevent page from visiting robots.txt
- avoiding mirrors and duplicate pages avoid-page-duplication
- maintain politeness - don't hit a server too often
- Refresh Strategies freshness
- Speeding up DNS lookup
7.1.4.1.2.5. Policies of web crawler
The behavior of a Web crawler is the outcome of a combination of policies :
- A selection policy that states which pages to download
- A revisit policy that states when to check for changes to the pages
- A politeness policy that states how to avoid overloading websites
- A parallelization policy that states how to coordinate distributed web crawlers.
7.1.4.2. Simplest Crawler Operation (Crawling Algorithm Version 01)
Begin with known "seed" page, fetch and parse a page(extract the URLs within the page and put them on a queue), fetch each URL on the queue and repeat.
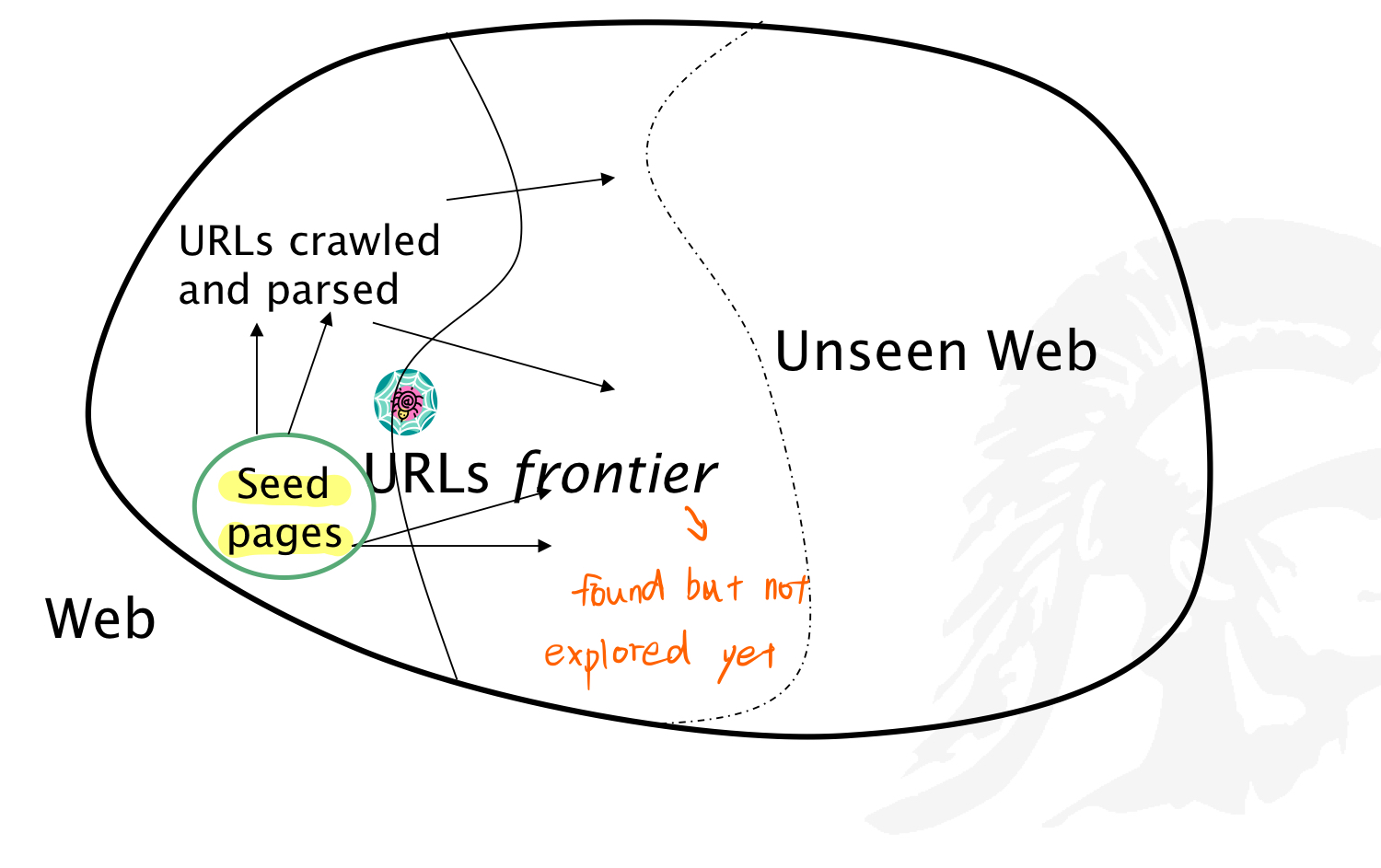
7.1.4.3. Robots.txt
defines the limitations for a web crawler as it visit a website. The website announces its request on what can/can't be crawled by placing a robots.txt file in the root directory.
7.1.4.4. Basic Search Strategies
7.1.4.4.1. Breadth first search
BFS crawling brings in high quality pages early in the crawl.
7.1.4.4.2. Depth first search

How the new links are added to the queue determines the search strategy.
- FIFO(append to end of Q) gives breadth-first-search.
- LIFO(append to front of Q) gives depth-first-search.
- Heuristically ordering the Q gives a "focused crawler"
- Move forward URLs whose In-degree is large
- Move forward URLs whose PageRank is large
7.1.4.5. Avoid Page Duplication
A crawler must detect that when revisiting a page that has already been crawled. Therefore, a crawler must efficiently index URLs as well as already visited pages.
The web is a graph not a tree.
- determine if a URL has already been seen representing-urls
- store URL in standard format
- develop a fast way to check if a URL has already been seen
- determine if a new page has been seen
- develop a fast way to determine if an identical or near-identical page was already indexed
7.1.4.5.1. Link Extraction
- Must find all links in a page and extract URLs
- Relative URL's must be completed, using current page URL or \base\ tage
7.1.4.5.1.1. Two anomalies
- Some anchor don't have links
- SOme anchor produce dynamic pages which can lead to looping
7.1.4.5.1.2. Representing URLs
One Proposed Method
- First hash on host/domain name
- then, use a trie data structure to determine if the path/resource is the same on one in the database
Trie for URL Exact Matching
Characteristics of tries
- They share the same prefix among multiple "words"
- Each path from the root to a leaf corresponds to one "word"
- EndMarker symbol
$at the ends of words: To avoid confusion between words with almost identical elements - For
nURLs and maximum lengthk, time is
Another Proposed Method
URLs are sorted lexicographically and then stored as a delta-encoded test file
- Each entry is stored as the difference(delta) between the current and previous URL; this substantially reduces storage
- However, the restoring the actual URL is slower
- TO improve speed, checkingpointing(storing the full URL) is done periodically
7.1.4.5.1.3. Why Normalizing URLs is Important?
People can type URL in different way but they all point to the same place. e.g. http://www.google.com and google.com
Normalizing URLs(4 rules)
- Convert scheme and host to lower case.
- Capitalize letters in escape sequences.
- Decode precent-encoded octets of unreserved characters.
- Remove the default port.
7.1.4.6. Avoid Spider Traps
A spider trap is when a crawler re-visits the same page over and over again. The most well-known spider trap is the one created by the use of Session ID

7.1.4.7. Handling Spam
- First Generation : consisted of pages with a high number of repeated terms
- Second Generation : cloaking ==> return different pages to crawler and users
- Third Generation : doorway page ==> contain highly ranked text and metadata
7.1.4.8. The Mercator Web Crawler

7.1.4.9. Measuring and Tuning a Crawler reduces to:
- Improving URL parsing speed
- Improving network bandwidth speed
- Improving fault tolerance
7.1.4.10. DNS caching, pre-fetching and resolution
- DNS caching : build a caching server that retains IP-domain name mappings previously discovered
- Pre-fetching client: once the page is parsed immediately make DNS resolution requests to the caching server; if unresolved, use UDP(User Datagram Protocol) to resolve from the DNS server.
- Customize the crawler so it allows issuing of many resolution requests simultaneously; there should be many DNS resolvers.
7.1.4.11. Multi-Threaded Crawling
One bottleneck is network delay in downloading individual pages.
It is best to have multiple threads running in parallel each requesting a page from a different host.
- thread : a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler.
- In most cases, a thread is a component of a process.
- Multiple threads can exist within the same process and share resources.
7.1.4.12. Distributed Crawling Approache
Distributed URL's to threads to guarantee equitable distribution of requests across different hosts maximize through-put and avoid overloading any single server.
- How many crawlers should be running at any time?
- Scenario 1: A centralized crawler controlling a set of parallel crawlers all running on a LAN
- Scenario 2: A distributed set of crawlers running on widely distributed machines, with or without cross communication.
7.1.4.12.1. Distributed Model


Three strategies of Coordination of Distributed Crawling :
- Independent : no coordination, every process follows its extracted links
- Dynamic assignment : a central coordinator dynamically divides the web into small partitions and assign each partition to a process
- Static assignment : web is partitioned and assigned without a central coordinator before the crawl starts
- inter-partition links can be handled in three ways as follow :

- Firewall mode
- Cross-over mode
- Exchange mode(communication required):
- Batch communications : every process collects some URLs and sends them in a batch
- Replication: the k most popular URLs are replicated at each process and not exchanged
- inter-partition links can be handled in three ways as follow :
7.1.4.12.1.1. Some ways to partition the Web:
- URL-hash based : this yields many inter-partition links
- Site-hash based : reduces the intern-partition links
- Hierarchical : by TLD(Top-Level-Domain)
7.1.4.12.2. General Conclusions of Cho and Garcia-Molina
- Firewall crawlers attain good, general coverage with low cost
- Cross-over ensures 100% quality, but suffer from overlap
- Replicating URLs and batch communication can reduce overhead
7.1.4.13. Freshness
how fresh the page in our database compared to the page out there
Web is very dynamic : many new pages, updated pages and deleted pages, etc.

7.1.4.13.1. Cho and Garcia-Molina Experiment
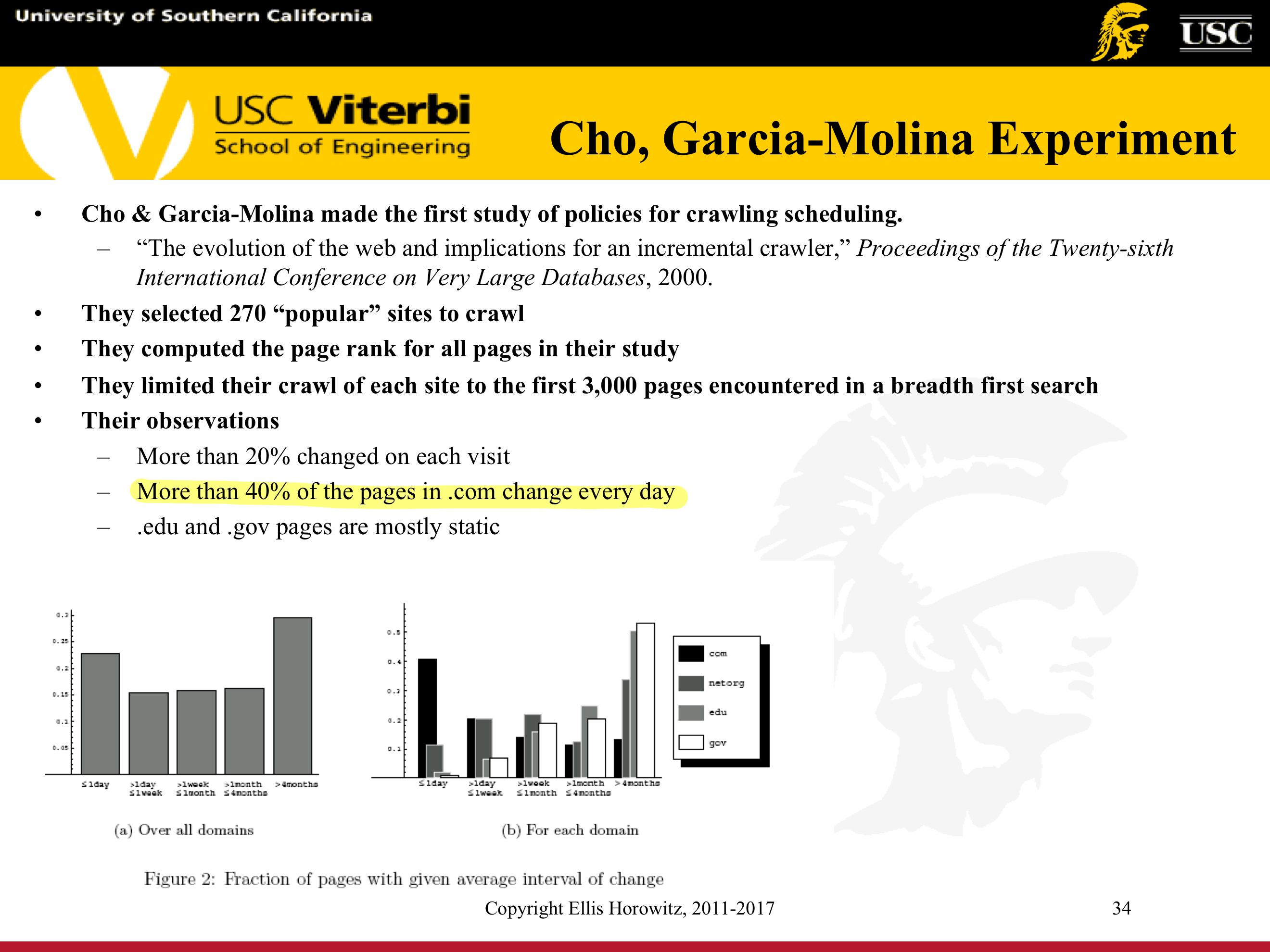
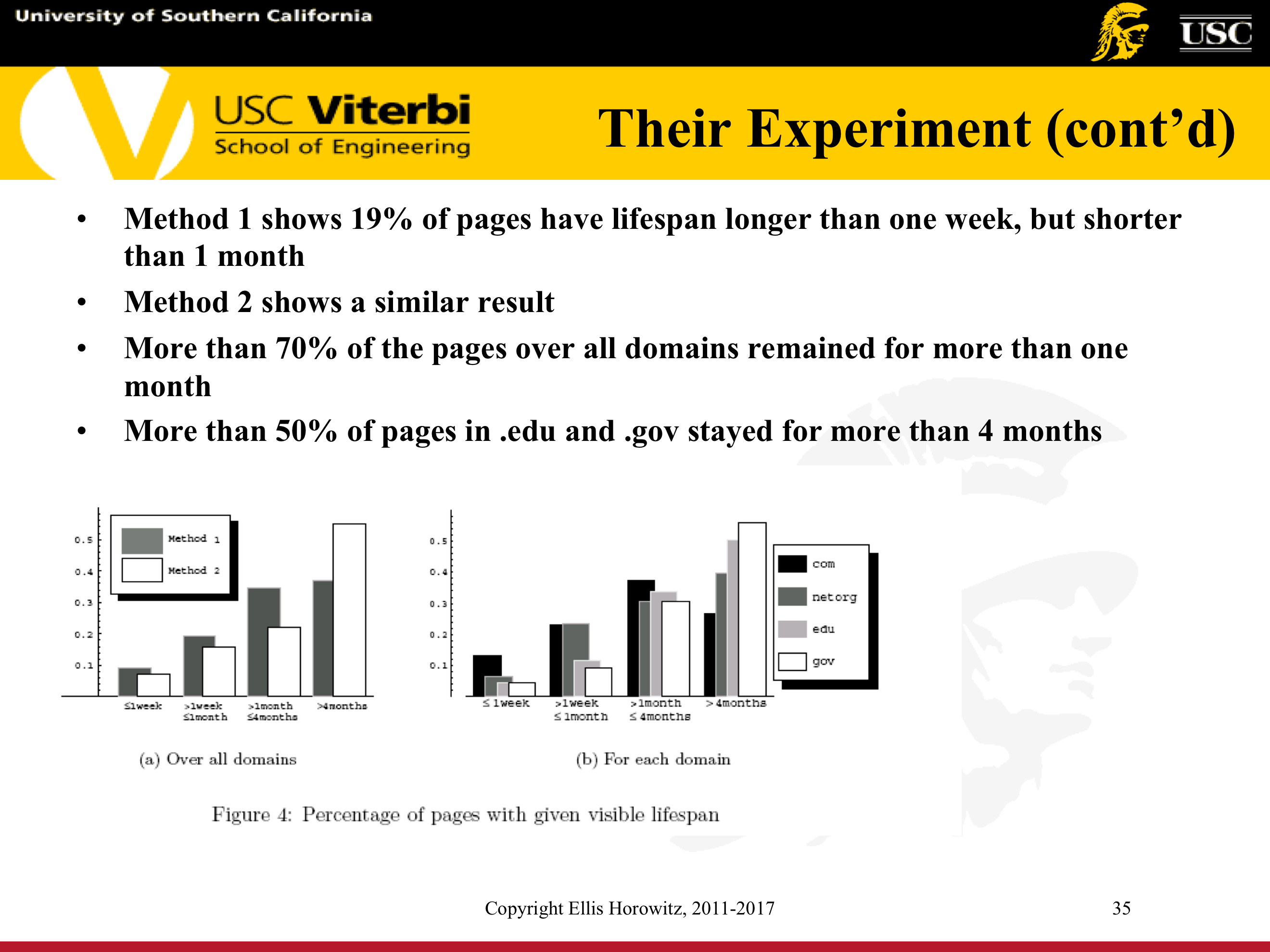
7.1.4.13.2. Implications for a Web Crawler

7.1.4.13.3. Change Frequency vs. Optimal Re-visiting

7.1.4.13.4. Cho and Garcia-Molina
Two simple re-visiting policies:
- Uniform policy : with same frequency
- Proportional Policy : re-visiting more often the pages that change more frequently
The uniform policy outperforms the proportional policy.
The explanation for this result comes from the fact that, when a page changes too often, the crawler will waste time by trying to re-crawl it too fast and still will not be able to keep its copy of the page fresh.
To improve freshness, we should penalize the element that change to fast.
7.1.4.14. SiteMap
A sitemap is a list of pages of a web site accessible to crawlers.
- XML is used as the standard for representing sitemaps. contains
<loc>,<lastmod>,<changefreq>, and<priority>
7.1.4.15. URL frontier Using Mercator schema








- kind of round-robin
- give different probilities







